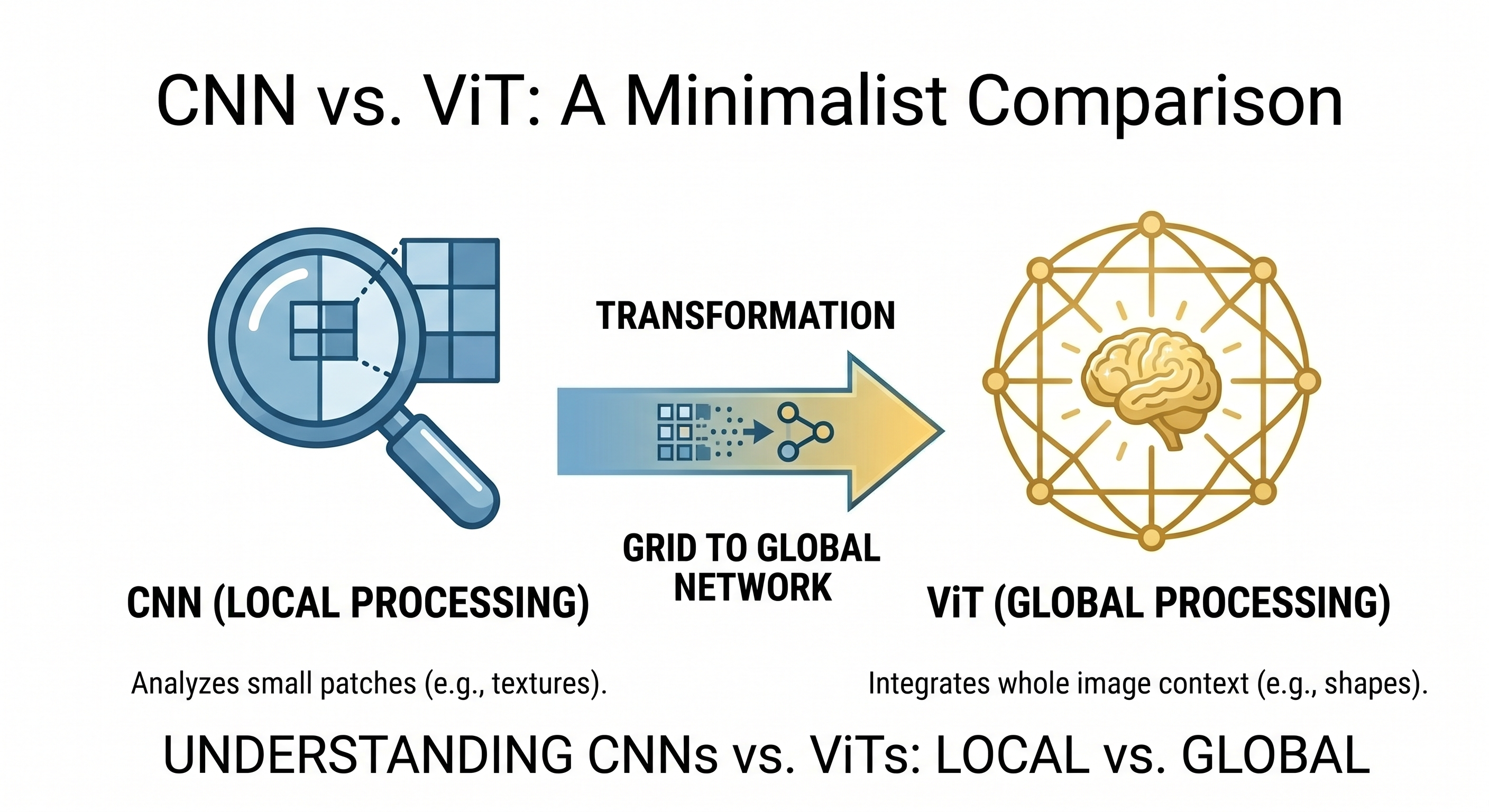
For years, Convolutional Neural Networks dominated computer vision. However, transformer architectures originally designed for NLP are now revolutionizing image understanding. Vision Transformers (ViTs) have become one of the most influential breakthroughs in deep learning.
How Vision Transformers Work
Instead of processing images with convolutions, ViTs divide images into smaller patches and treat them similarly to tokens in NLP models.
- Image is split into fixed-size patches.
- Each patch is embedded into a vector.
- Positional embeddings preserve spatial information.
- Transformer encoder layers process relationships between patches.
Why ViTs Are Powerful
Transformers excel at learning long-range dependencies. Unlike CNNs, which focus locally through convolution kernels, ViTs can directly model global image relationships.
PyTorch ViT Example
import torch
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
# Load pretrained model
model = ViTForImageClassification.from_pretrained(
"google/vit-base-patch16-224"
)
feature_extractor = ViTFeatureExtractor.from_pretrained(
"google/vit-base-patch16-224"
)
# Load image
url = "https://images.unsplash.com/photo-example"
image = Image.open(requests.get(url, stream=True).raw)
# Preprocess image
inputs = feature_extractor(
images=image,
return_tensors="pt"
)
# Run inference
outputs = model(**inputs)
# Predicted class
predicted_class = outputs.logits.argmax(-1)
print("Predicted class index:", predicted_class.item())
Applications of Vision Transformers
- Medical Imaging
- Autonomous Vehicles
- Satellite Image Analysis
- Facial Recognition
- Video Understanding
Limitations of ViTs
- Require very large datasets for training.
- High computational costs.
- Inference can be slower compared to lightweight CNNs.
The Future of Vision AI
Hybrid architectures combining CNNs and transformers are emerging rapidly. As hardware accelerators improve, Vision Transformers are expected to dominate next-generation multimodal AI systems.
"Transformers did not stop at language — they are reshaping how machines understand the visual world." - Ashish Gore