For years, Large Language Models (LLMs) have demonstrated a remarkable ability to understand and generate text. However, they were fundamentally "blind," living in a world of words alone. The latest evolution in AI, Vision-Language Models (VLMs), changes everything. These are multimodal models, like OpenAI's GPT-4o and Google's Gemini, that can simultaneously process and reason about images, video, and text, creating a far more comprehensive understanding of the world.
How Do VLMs Work? A Simple Explanation
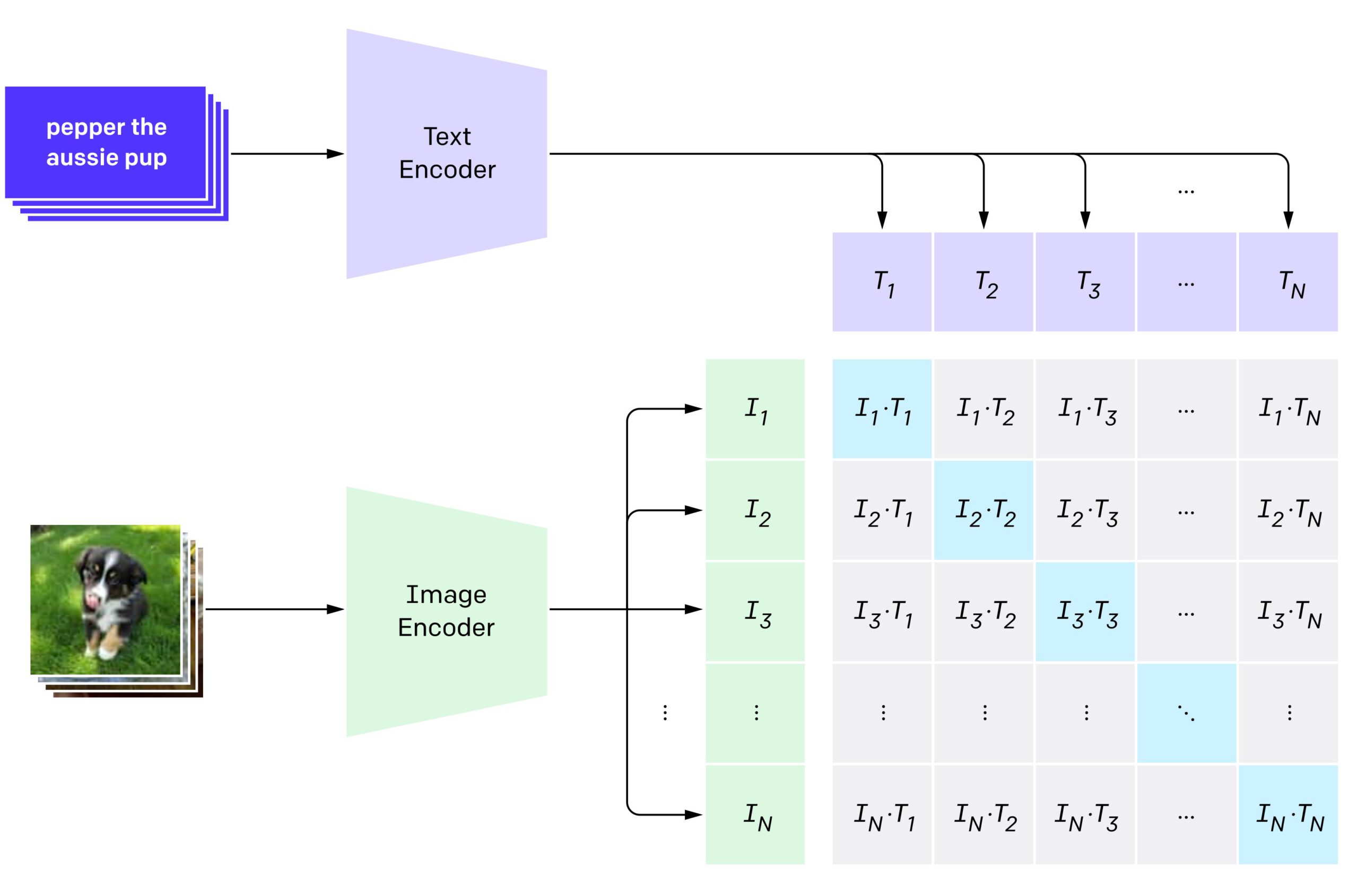
At their core, VLMs bridge the gap between two major fields of AI: Computer Vision and Natural Language Processing. They typically consist of three main components:
- A Vision Encoder: This part of the model acts like the "eyes." It uses a technique like a Vision Transformer (ViT) to analyze an image and convert its visual features into a numerical representation (embeddings).
- A Language Model: This is a standard LLM that excels at understanding and generating text.
- A Connector Module: This crucial piece acts as a translator, converting the numerical "image language" from the vision encoder into a format that the language model can understand.
By combining these components, a VLM can take both an image and a text prompt as input and generate a coherent, context-aware response that incorporates information from both modalities.
What Can VLMs Do? Key Applications
This ability to "see" and "read" at the same time unlocks a vast range of new applications:
- Visual Question Answering (VQA): Ask detailed questions about an image, such as "What type of plant is on the windowsill?" or "Based on this graph, which quarter had the highest revenue?"
- Rich Image Captioning: Go beyond simple labels to generate detailed, narrative descriptions of what is happening in a photo or work of art.
- Multimodal Instruction Following: Show the model a picture of ingredients in your fridge and ask, "What can I make for dinner with these?"
- Enhanced Accessibility: Provide real-time descriptions of a user's surroundings for visually impaired individuals.
A Practical Code Example with Hugging Face
Thanks to the open-source community, you can experiment with powerful VLMs with just a few lines of code. The following example uses the Hugging Face `transformers` library to perform Visual Question Answering with Salesforce's BLIP model.
# A practical example of using a VLM with Hugging Face Transformers
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForQuestionAnswering
# 1. Load a pre-trained VLM for Visual Question Answering
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
model = BlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
# 2. Load a sample image from the web
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# 3. Prepare the text prompt (the question)
question = "what is the woman doing?"
# 4. Process the image and text together
inputs = processor(raw_image, question, return_tensors="pt")
# 5. Generate an answer from the model
out = model.generate(**inputs)
answer = processor.decode(out[0], skip_special_tokens=True)
print(f"Question: {question}")
print(f"Answer: {answer}")
# Expected output: "a woman is sitting on the beach with a dog"
The Future and Its Challenges
VLMs are rapidly advancing and will soon enable more intuitive human-computer interfaces, smarter robotics, and revolutionary accessibility tools. However, challenges remain. Like their text-only predecessors, VLMs can "hallucinate" details not present in an image, inherit societal biases from their training data, and are computationally expensive to train and operate. Addressing these issues is key to their responsible development.
Conclusion
Vision-Language Models represent a monumental step toward more general and capable AI. By giving language models the ability to see, we are creating systems that can perceive, understand, and interact with the world in a way that is far more aligned with human cognition. As this technology matures, it will undoubtedly reshape our digital experiences and open up possibilities we are only just beginning to imagine.
"Giving language models 'eyes' was the natural next step. True AI understanding requires perceiving the world, not just reading about it." - Ashish Gore
If you're interested in exploring how multimodal AI can be applied to your specific domain, feel free to connect through my contact information.