Transformers changed how we build models for language. In a few years they moved NLP from carefully engineered pipelines to models that learn representations from raw text at scale. This post walks through why transformers work, the important variants from BERT to GPT, their practical trade offs, and where the field is headed. I will focus on concepts you can use when designing models and systems for real projects.
Why transformers made a difference
Before transformers, recurrent and convolutional architectures dominated sequence tasks. They handled context but had limits. Recurrent models process tokens one at a time. That makes it hard to parallelize training and to capture very long range dependencies. Self attention introduced two practical advantages.
- Global context in one operation. Each token can attend to every other token via scaled dot product attention. You do not need many recurrent steps to propagate information across a long sequence.
- Parallelism during training. Attention computes interactions between tokens in parallel. This unlocks efficient GPU utilization and enables training on far larger datasets.
These points are the practical reason transformer models scaled quickly and why they are the backbone of modern NLP, vision, and multi modal models.
Core building blocks
At the heart of a transformer are a few simple components. Understanding them helps when you tune or adapt architectures.
Self attention
Given token embeddings X, attention computes three projections: queries Q, keys K, and values V. Attention scores are softmax(QK^T / sqrt(d_k)) applied to V. This produces a weighted mixture of values where weights reflect token similarity.
Q = X W_q
K = X W_k
V = X W_v
Attention(Q, K, V) = softmax(Q K^T / sqrt(d_k)) VMulti head attention
Instead of one attention, multiple parallel attention heads operate in different subspaces. Their outputs are concatenated and linearly projected. Multi head attention helps the model capture diverse relationships at different scales.
Position encoding
Transformers are permutation invariant. To encode token order we add position embeddings. These can be fixed sinusoidal encodings or learned vectors. Many downstream behaviors depend on how positional information is represented.
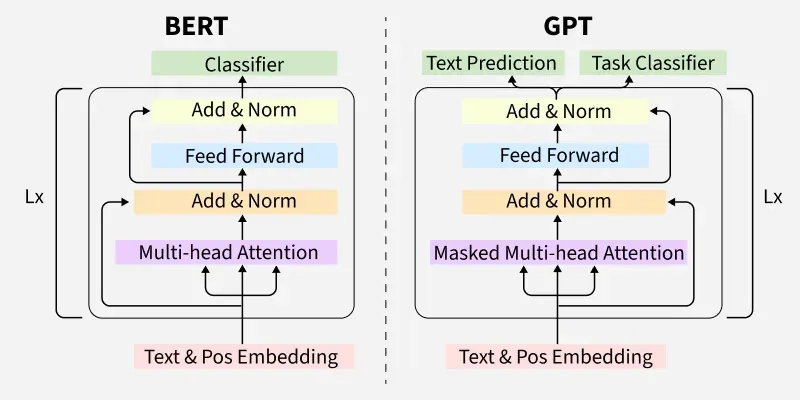
BERT vs GPT: two uses of the same primitive
BERT and GPT use the same transformer building blocks but differ in objective and directionality. That difference changes what they are best at.
BERT: bidirectional encoder
BERT is trained with masked language modeling where some tokens are masked and the model predicts them using both left and right context. That creates rich contextual representations that work well for classification, named entity recognition, and sentence pair tasks.
GPT: autoregressive decoder
GPT is trained to predict the next token given previous tokens. It is directional and excels at generation. GPT style models are the ones behind chatbots and many content generation systems.
Practical trade offs
When choosing a transformer variant consider these trade offs.
- Pretraining objective. Masked objectives produce better encoders for classification. Autoregressive objectives produce stronger generators. The choice depends on whether you need encoding quality or generation fluency.
- Computation and memory. Attention is quadratic in sequence length. For long documents you must choose sparse or hierarchical attention or chunking strategies to keep costs manageable.
- Fine tuning vs prompt tuning. Full fine tuning gives best task performance but requires storing a model per task. Adapter or LoRA style parameter efficient methods let you adapt large models cheaply while keeping the base model unchanged.
Beyond the original transformer: important variants
Researchers and engineers extended transformers to address limits in cost, context length, modality, and reasoning. Here are practical families you should know about.
Efficient attention
Many works reduce the quadratic cost of attention. Sparse attention uses patterns so each token attends only to a subset. Linear attention approximates softmax with kernel tricks to make attention linear in sequence length. These approaches allow processing longer sequences but may trade off some accuracy.
Encoder-decoder and sequence to sequence
Encoder-decoder transformers work well for translation and summarization. The encoder produces a representation for the whole input. The decoder autoregressively generates output while attending to encoder outputs. This architecture is a good starting point when your task requires conditional generation.
Pretraining recipes
New objectives combine multiple losses. Electra uses a discriminator that learns to spot replaced tokens. T5 framed text tasks as a text to text problem and showed the benefit of unified objective design. These choices affect sample efficiency and downstream transfer.
Multi modal transformers
By adding image or audio projections into the transformer you can build models that jointly reason about different modalities. These models are increasingly relevant for applications that combine text with images or speech.
Engineering patterns for production
Transformers are powerful but must be deployed thoughtfully. I have used the patterns below in production systems and they consistently help.
1. Use parameter efficient adapters
Adapters or LoRA let you keep a single base model and load small task specific adapters. This makes updates cheaper and reduces storage footprint for many tasks.
2. Chunk long inputs and do reranking
For long documents split into chunks, encode each chunk, and then rerank or aggregate. For tasks like question answering this approach often outperforms trying to process everything at once.
3. Monitor drift and calibration
Pretrained models drift when input distribution changes. Build monitoring dashboards for confidence scores and key metrics. Use calibration techniques if your model over or under estimates uncertainty.
4. Cost control
Use smaller models for routine tasks and reserve large models for high value requests. Cache responses for repeating queries, shard traffic between models, and use distillation for latency sensitive endpoints.
Where the field is heading
Expect several trends to shape how transformers evolve in the near future.
- Long context transformers. Applications that require document level understanding will push better efficient attention and memory mechanisms.
- Better reasoning. Architectural and training changes that improve systematic reasoning will be a key focus.
- Multi modal integration. Models that natively combine text, vision, and other modalities will become standard for product use cases.
- Model modularity. Systems built from interchangeable components will simplify updates and allow safer governance.
Quick reference recipes
Practical snippets you can use when experimenting.
# 1. Chunking strategy for long documents
chunks = [doc[i:i+max_tokens] for i in range(0, len(doc), max_tokens)]
embeddings = [encoder(chunk) for chunk in chunks]
# store in vector DB and do retrieval on top-k chunks
# 2. Adapters (LoRA) conceptually
# keep base model frozen and learn small low rank matrices for attention projections
Conclusion
Transformers are a versatile and scalable architecture that reshaped NLP. The core idea is simple. Use attention to let tokens interact directly and train with objectives that transfer across tasks. From that base we now have models specialized for encoding, models specialized for generation, and many efficient variants that let us handle longer inputs or multiple modalities. When designing systems, focus on the objective that matches your task, manage sequence length and cost, and prefer parameter efficient adaptation when you need many task specific models.
"The transformer is more than a model. It is a platform that lets us explore model objectives, scale, and system design in ways that were not practical before." - Ashish Gore
If you want, I can also prepare a short slide deck highlighting the key diagrams and code snippets from this post that you can use in talks or interviews. Or I can generate a shorter summary suitable for the blog posts listing page.