Large Language Models are impressive, but they come with a fundamental limitation: their knowledge is frozen at the time of training. Ask a model about last week's news or your company's internal documentation, and it will either hallucinate an answer or admit ignorance. Retrieval-Augmented Generation (RAG) is the architectural pattern that solves this problem, and it has rapidly become one of the most important techniques in production AI development.
What Is RAG and Why Does It Matter?
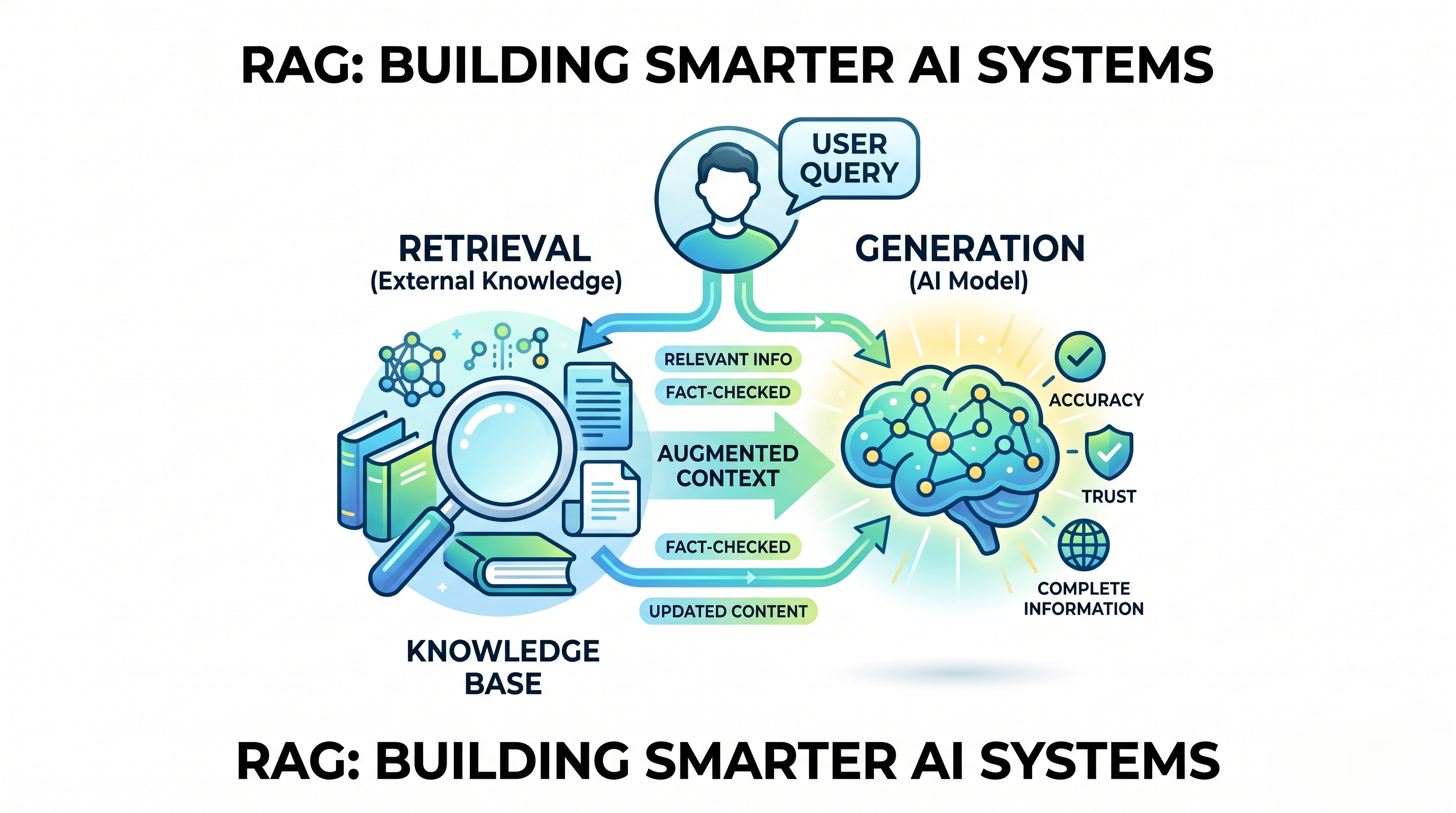
RAG is a hybrid AI architecture that combines the reasoning power of a language model with a dynamic, searchable knowledge base. Instead of relying solely on what the model learned during training, a RAG system first retrieves relevant documents from an external source and then passes those documents — along with the user's question — to the LLM to generate a grounded, accurate answer.
This addresses three critical pain points in production LLM deployments:
- Hallucination Reduction: The model is anchored to real retrieved text, dramatically reducing the chances of fabricating facts.
- Knowledge Freshness: Your knowledge base can be updated without retraining the entire model — simply add new documents to the vector store.
- Domain Specialization: You can build AI assistants that are experts in your proprietary data — legal contracts, medical records, internal wikis — without fine-tuning.
The RAG Pipeline: Step by Step
A standard RAG pipeline consists of two distinct phases — an offline indexing phase and an online retrieval-and-generation phase.
- 1. Document Ingestion & Chunking: Raw documents (PDFs, web pages, text files) are split into smaller, semantically meaningful chunks. Chunk size is a critical hyperparameter — too small and context is lost; too large and retrieval precision suffers.
- 2. Embedding Generation: Each chunk is converted into a dense vector (embedding) using a model like
text-embedding-ada-002or an open-source alternative likesentence-transformers. These vectors capture semantic meaning, not just keywords. - 3. Vector Store Indexing: The embeddings are stored in a vector database such as FAISS, Pinecone, Chroma, or Weaviate, which is optimized for fast similarity search.
- 4. Query Time — Retrieval: When a user submits a query, it is also converted into an embedding. The vector store performs a nearest-neighbor search to find the top-k most semantically similar document chunks.
- 5. Augmented Generation: The retrieved chunks and the original query are combined into a structured prompt, which is sent to the LLM. The model generates its final response grounded in this retrieved context.
A Practical Code Example with LangChain and ChromaDB
The following example demonstrates a minimal but fully functional RAG pipeline using LangChain, ChromaDB as the vector store, and OpenAI embeddings. You can swap any component for open-source alternatives.
# Building a RAG pipeline with LangChain and ChromaDB
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ── Step 1: Load and chunk your documents ──────────────────────────
loader = TextLoader("company_handbook.txt")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # characters per chunk
chunk_overlap=50 # overlap to preserve context at boundaries
)
chunks = splitter.split_documents(documents)
# ── Step 2: Embed and store in ChromaDB ────────────────────────────
embeddings = OpenAIEmbeddings() # or use HuggingFaceEmbeddings for OSS
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db" # persists to disk
)
# ── Step 3: Build the retrieval-augmented QA chain ─────────────────
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # stuffs all retrieved docs into context
retriever=vectorstore.as_retriever(search_kwargs={"k": 4}),
return_source_documents=True
)
# ── Step 4: Ask a question ─────────────────────────────────────────
query = "What is the company's policy on remote work?"
result = qa_chain({"query": query})
print(f"Answer: {result['result']}")
print("\nSources used:")
for doc in result["source_documents"]:
print(f" - {doc.metadata.get('source', 'unknown')} | {doc.page_content[:100]}...")
Advanced RAG Techniques
Basic RAG works well, but production systems often require more sophistication. Hybrid Search combines dense vector retrieval with traditional sparse keyword search (BM25) to handle both semantic and exact-match queries. Reranking adds a second-stage model (like Cohere's Rerank API) to re-score the initially retrieved chunks before passing them to the LLM, significantly improving precision. HyDE (Hypothetical Document Embeddings) generates a hypothetical answer first, embeds it, and uses that to retrieve documents — often outperforming direct query embedding. Finally, GraphRAG, pioneered by Microsoft, builds a knowledge graph from documents to enable multi-hop reasoning across related entities.
When NOT to Use RAG
RAG is not always the right tool. If your task requires the model to learn new reasoning patterns or adapt its style, fine-tuning is more appropriate. RAG retrieves factual grounding — it cannot teach the model new skills. Additionally, poorly chunked or low-quality knowledge bases will yield poor results regardless of the LLM quality. Garbage in, garbage out still applies. Latency is also a consideration: a RAG pipeline adds retrieval time to every inference call, which may be unacceptable in latency-sensitive applications.
Conclusion
Retrieval-Augmented Generation represents a pragmatic and powerful bridge between the vast reasoning capabilities of LLMs and the ever-changing, domain-specific knowledge of the real world. By keeping knowledge external and retrievable, RAG systems are cheaper to update, more accurate, and more trustworthy than a pure parametric model. For any developer building production AI applications today, RAG is an essential pattern to master.
"The most robust AI systems don't just know things — they know how to find things. RAG gives language models a library card, not just a textbook." - Ashish Gore
If you're interested in building a custom RAG pipeline for your organization's data, feel free to connect through my contact information.