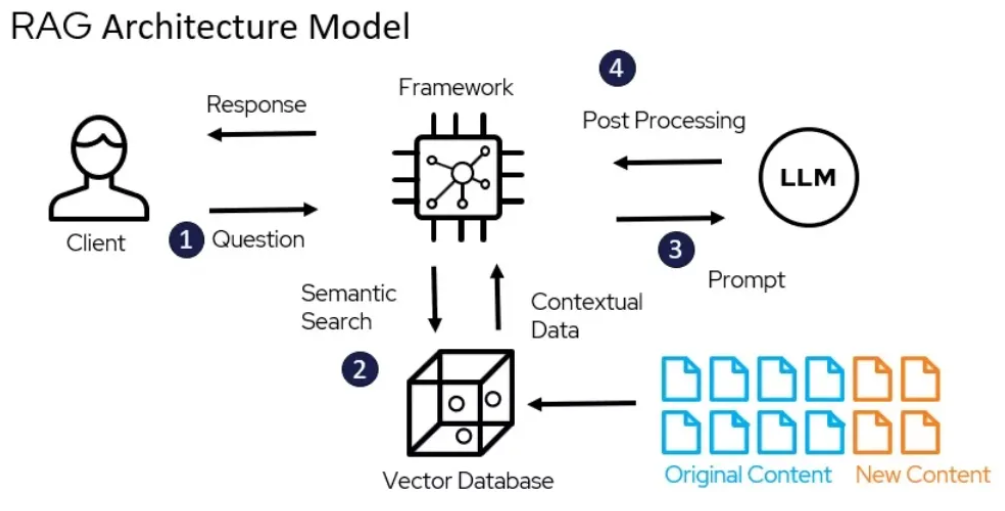
Retrieval-Augmented Generation (RAG) has revolutionized how we build AI applications by combining the power of large language models with external knowledge retrieval. In this comprehensive guide, I'll walk you through building production-ready RAG systems based on my experience implementing them at bluCognition.
What is RAG and Why Does It Matter?
RAG addresses a critical limitation of LLMs: their knowledge is static and limited to their training data. By retrieving relevant information from external sources and providing it as context to the LLM, RAG systems can deliver accurate, up-to-date responses while reducing hallucinations.
In production environments, RAG systems must handle:
- Real-time query processing
- Scalable vector search
- Context window management
- Response quality monitoring
- Cost optimization
Architecture Components
A robust RAG system consists of several key components:
1. Document Processing Pipeline
The first step is ingesting and processing your knowledge base. This involves:
- Document Chunking: Split documents into optimal-sized chunks (typically 200-500 tokens)
- Metadata Extraction: Capture document source, timestamps, and other relevant metadata
- Text Preprocessing: Clean and normalize text for better embedding quality
2. Embedding Generation
Convert text chunks into vector embeddings using models like:
- OpenAI's text-embedding-ada-002
- Sentence-BERT models
- Custom fine-tuned embeddings
3. Vector Database
Store and search embeddings efficiently using:
- Pinecone: Managed vector database with excellent performance
- Weaviate: Open-source option with hybrid search capabilities
- FAISS: Facebook's library for similarity search
Implementation Best Practices
Query Processing
Effective query processing involves multiple strategies:
def process_query(query, vector_db, llm_client):
# 1. Query expansion
expanded_query = expand_query(query)
# 2. Hybrid search (semantic + keyword)
semantic_results = vector_db.similarity_search(expanded_query, k=10)
keyword_results = keyword_search(query, k=5)
# 3. Re-ranking
reranked_results = rerank_results(semantic_results, keyword_results)
# 4. Context assembly
context = assemble_context(reranked_results[:5])
# 5. LLM generation
response = llm_client.generate(query, context)
return responseContext Management
Managing context within token limits is crucial:
- Implement dynamic context selection based on relevance scores
- Use sliding window approaches for long documents
- Prioritize recent and authoritative sources
Production Considerations
Performance Optimization
To ensure your RAG system performs well under load:
- Implement caching for frequent queries
- Use async processing for non-blocking operations
- Optimize vector search with proper indexing
- Monitor response times and throughput
Quality Assurance
Maintain response quality through:
- Automated testing with ground truth datasets
- Human evaluation workflows
- Feedback collection and analysis
- A/B testing for different retrieval strategies
Monitoring and Observability
Track key metrics including:
- Query response time
- Retrieval accuracy
- Generation quality scores
- User satisfaction ratings
- Cost per query
Common Pitfalls and Solutions
1. Poor Chunking Strategy
Problem: Chunks too small lose context, too large exceed token limits.
Solution: Use semantic chunking with overlap and experiment with different sizes.
2. Inadequate Retrieval Quality
Problem: Retrieved documents don't match query intent.
Solution: Implement query expansion, use hybrid search, and fine-tune embedding models.
3. Context Window Issues
Problem: Important information gets cut off due to token limits.
Solution: Implement smart context selection and summarization techniques.
Advanced Techniques
Multi-Modal RAG
Extend RAG to handle images, tables, and other data types by using multi-modal embedding models and specialized retrieval strategies.
Conversational RAG
Maintain conversation context across multiple turns by storing conversation history and using it to improve retrieval and generation.
Real-Time Updates
Implement incremental indexing to keep your knowledge base current without full re-indexing.
Conclusion
Building production-ready RAG systems requires careful attention to architecture, performance, and quality. By following these best practices and continuously monitoring and improving your system, you can create RAG applications that deliver accurate, helpful responses at scale.
Remember that RAG is not a one-size-fits-all solution. Tailor your approach based on your specific use case, data characteristics, and performance requirements. Start simple, measure everything, and iterate based on real-world feedback.
"The key to successful RAG implementation is not just technical excellence, but understanding your users' needs and continuously improving based on their feedback." - Ashish Gore
If you're interested in learning more about RAG systems or have questions about implementing them in your organization, feel free to reach out through my contact information.