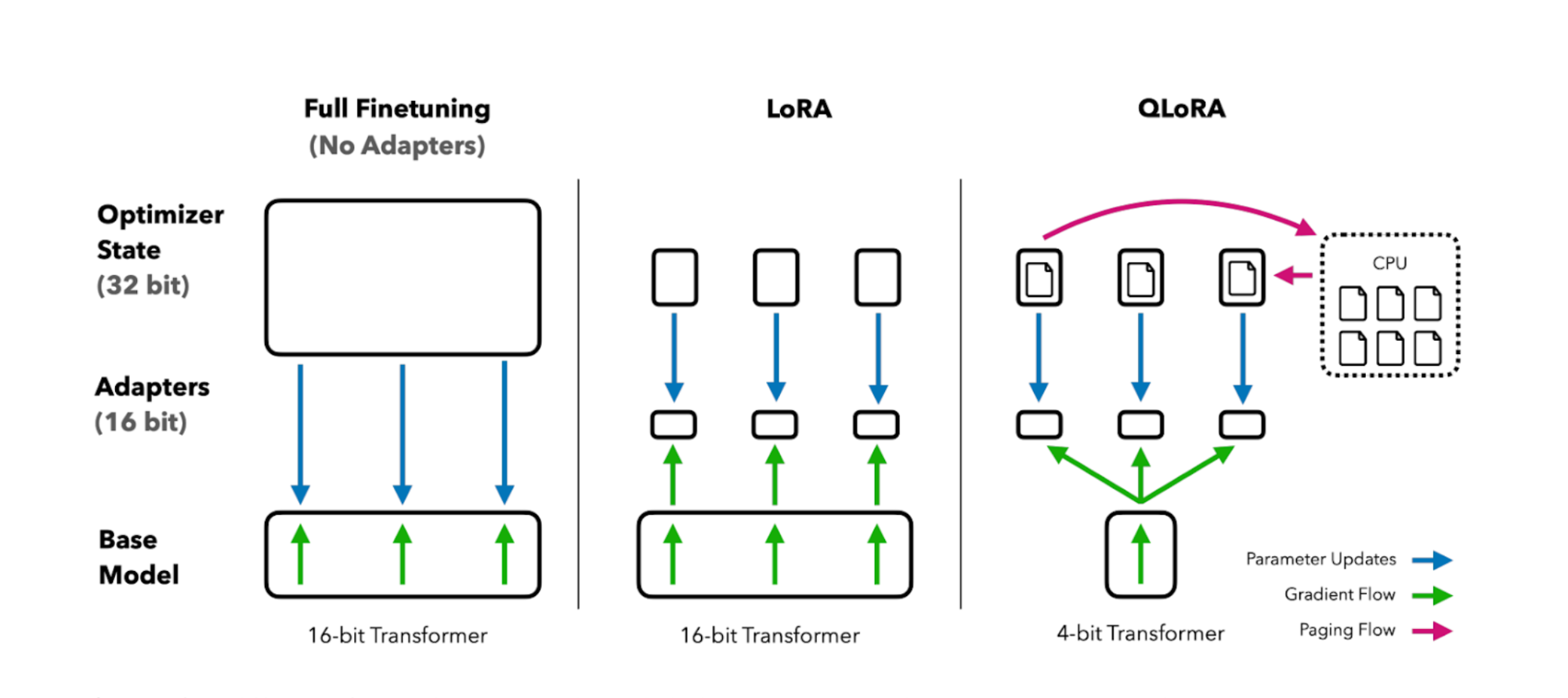
Fine-tuning large language models for specific domains has become essential for building effective AI applications. However, traditional full fine-tuning is computationally expensive and often impractical. In this post, I'll explore LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) techniques that make efficient fine-tuning accessible to everyone.
The Challenge with Full Fine-tuning
Traditional fine-tuning involves updating all parameters of a pre-trained model, which presents several challenges:
- Memory Requirements: 7B+ parameter models require 40GB+ GPU memory
- Computational Cost: Training can take days and cost thousands of dollars
- Storage Overhead: Each fine-tuned model requires full storage of all parameters
- Catastrophic Forgetting: Risk of losing general capabilities while gaining domain-specific ones
Understanding LoRA (Low-Rank Adaptation)
LoRA addresses these challenges by introducing low-rank matrices that approximate the weight updates during fine-tuning. Instead of updating the original weights, LoRA learns small matrices that can be added to the original weights during inference.
Mathematical Foundation
For a pre-trained weight matrix W ∈ R^(d×k), LoRA represents the update as:
W + ΔW = W + BA
Where B ∈ R^(d×r) and A ∈ R^(r×k) are the low-rank matrices, and r << min(d,k) is the rank.
Key Advantages
- Reduced Memory: Only store r×(d+k) parameters instead of d×k
- Faster Training: Fewer parameters to update
- Modularity: Can add/remove LoRA adapters without retraining
- No Inference Overhead: Can merge adapters for production
Implementing LoRA with Hugging Face
Here's a practical implementation using the PEFT library:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
import torch
# Load model and tokenizer
model_name = "microsoft/DialoGPT-medium"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Configure LoRA
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16, # Rank
lora_alpha=32, # Scaling parameter
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"] # Which layers to apply LoRA to
)
# Apply LoRA to model
model = get_peft_model(model, lora_config)
# Training setup
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./lora-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=2e-4,
fp16=True,
save_steps=500,
logging_steps=100,
)
# Train the model
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
trainer.train()QLoRA: Quantized LoRA for Even Greater Efficiency
QLoRA extends LoRA by quantizing the base model to 4-bit precision, dramatically reducing memory requirements while maintaining performance.
Key Components of QLoRA
- 4-bit Quantization: Reduces model size by ~75%
- Double Quantization: Further reduces memory for quantization constants
- Paged Optimizers: Prevents memory spikes during training
- NormalFloat (NF4): Information-theoretically optimal data type
QLoRA Implementation
from transformers import BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
# Configure 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# Load quantized model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
# Prepare model for training
model = prepare_model_for_kbit_training(model)
# Configure LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
# Apply LoRA
model = get_peft_model(model, lora_config)Best Practices for LoRA/QLoRA Fine-tuning
1. Choosing the Right Rank
The rank parameter (r) controls the capacity of the adaptation:
- r=1-4: For simple tasks or when memory is extremely limited
- r=8-16: Good balance for most tasks
- r=32-64: For complex tasks requiring more adaptation
2. Target Module Selection
Focus on attention layers for most tasks:
- Attention layers: q_proj, k_proj, v_proj, o_proj
- MLP layers: gate_proj, up_proj, down_proj (for more capacity)
- All linear layers: Maximum adaptation but higher memory usage
3. Hyperparameter Tuning
Key parameters to optimize:
- Learning Rate: 1e-4 to 5e-4 (higher than full fine-tuning)
- LoRA Alpha: Usually 2x the rank value
- Dropout: 0.05 to 0.1 for regularization
- Batch Size: Adjust based on available memory
Real-World Applications
Domain-Specific Chatbots
Fine-tune models for specific industries like healthcare, finance, or legal services. The model learns domain-specific terminology and reasoning patterns.
Code Generation
Adapt models for specific programming languages or frameworks by training on relevant code repositories.
Creative Writing
Fine-tune for specific writing styles, genres, or brand voices while maintaining general language capabilities.
Performance Comparison
Based on my experience with various models and tasks:
| Method | Memory Usage | Training Time | Performance |
|---|---|---|---|
| Full Fine-tuning | 40GB+ | 24+ hours | 100% |
| LoRA | 8-12GB | 4-6 hours | 95-98% |
| QLoRA | 4-6GB | 2-4 hours | 90-95% |
Common Pitfalls and Solutions
1. Overfitting
Problem: Model performs well on training data but poorly on validation data.
Solution: Increase dropout, reduce learning rate, or use more diverse training data.
2. Catastrophic Forgetting
Problem: Model loses general capabilities while gaining domain-specific ones.
Solution: Mix domain-specific data with general data during training.
3. Poor Convergence
Problem: Model doesn't learn effectively from the training data.
Solution: Increase rank, adjust learning rate, or check data quality.
Deployment Considerations
Model Merging
For production deployment, you can merge LoRA adapters with the base model:
# Merge LoRA adapter with base model
merged_model = model.merge_and_unload()
# Save merged model
merged_model.save_pretrained("./merged-model")
tokenizer.save_pretrained("./merged-model")Dynamic Loading
For multi-tenant applications, keep adapters separate and load them dynamically based on user context.
Conclusion
LoRA and QLoRA have democratized LLM fine-tuning by making it accessible to organizations with limited computational resources. By following the best practices outlined in this post, you can effectively adapt large language models for your specific use cases while maintaining cost efficiency.
Remember that the key to successful fine-tuning is not just the technical implementation, but also having high-quality, diverse training data that represents your target domain well.
"The future of AI applications lies in specialized models that understand specific domains deeply while maintaining general capabilities. LoRA and QLoRA make this vision achievable for everyone." - Ashish Gore
If you're interested in implementing LoRA or QLoRA for your specific use case, feel free to reach out through my contact information for personalized guidance.