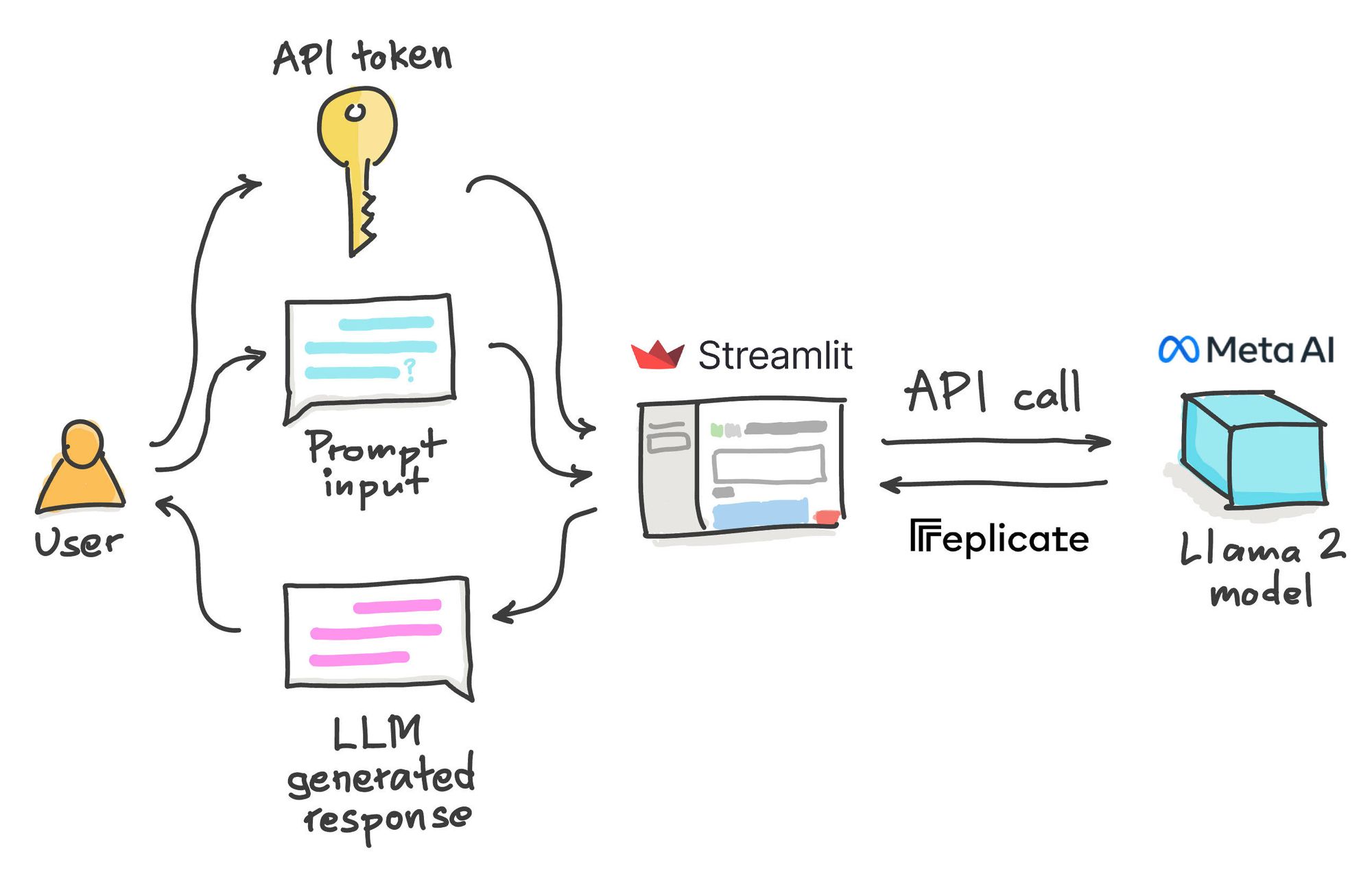
Meta’s LLaMA 3 models are among the most advanced open large language models (LLMs) available today. With strong instruction-following capabilities and support for fine-tuning, they provide an excellent foundation for building custom chatbots.
Why Choose LLaMA 3?
LLaMA 3 models are open, performant, and can be fine-tuned for specific use cases. Benefits include:
- Open Source: Transparent licensing for experimentation and deployment.
- Scalability: Available in multiple parameter sizes (8B, 70B, etc.).
- Performance: Competitive with proprietary models in benchmarks.
Setting Up the Environment
pip install transformers accelerate peft bitsandbytesfrom transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Llama-3-8b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)Fine-Tuning with PEFT
Parameter-Efficient Fine-Tuning (PEFT) lets you adapt large models with minimal compute cost.
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)Training on Domain Data
Prepare a dataset with your domain-specific Q&A pairs or conversations. Then use Hugging Face’s Trainer API to fine-tune:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./llama3-finetuned",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=2e-4,
logging_steps=10,
save_steps=500
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()Deploying the Chatbot
Once fine-tuned, you can deploy your chatbot using frameworks like FastAPI or Streamlit.
from fastapi import FastAPI
from transformers import pipeline
app = FastAPI()
chatbot = pipeline("text-generation", model="./llama3-finetuned")
@app.post("/chat")
def chat(user_input: str):
response = chatbot(user_input, max_length=200, do_sample=True)
return {"response": response[0]['generated_text']}Use Cases
- Customer Support: Automate FAQs and live support with tailored responses.
- Education: Provide tutoring and domain-specific knowledge.
- Healthcare: Assist with medical knowledge (with human oversight).
Best Practices
- Use quantization (4-bit, 8-bit) for cost-effective deployment.
- Implement caching for faster response times.
- Monitor outputs to ensure accuracy and safety in real-world use.
Conclusion
LLaMA 3 models make it possible to build robust, customized chatbots on open architectures. With PEFT fine-tuning and simple deployment setups, developers can create applications that rival proprietary solutions in capability while maintaining flexibility and control.
"Open models like LLaMA 3 empower developers to innovate without being locked into proprietary ecosystems." - Ashish Gore
If you’d like to deploy custom chatbots with LLaMA 3, feel free to reach out through my contact information.