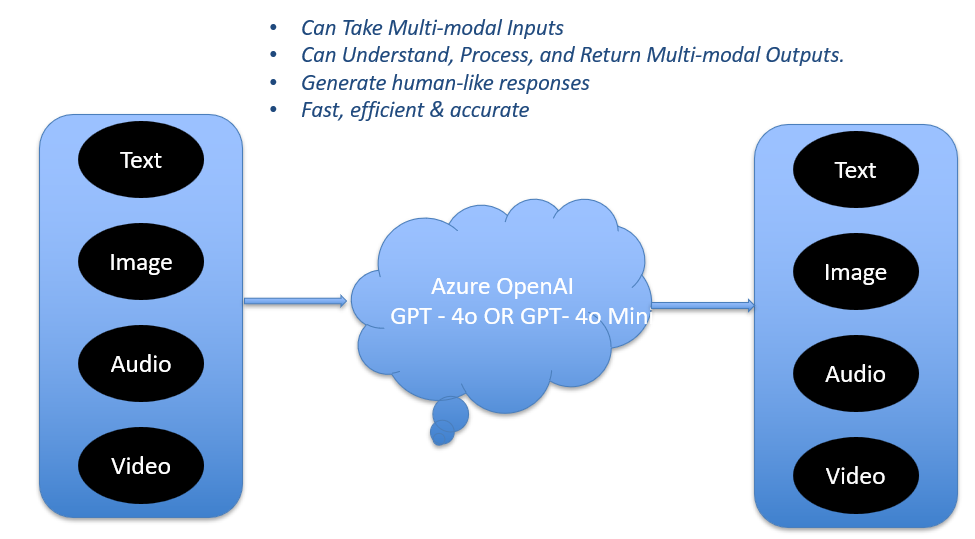
OpenAI’s GPT-4o, announced in 2024, represents a major leap in AI by natively supporting multiple input and output modalities. Unlike earlier models that handled only text or required add-ons for images and audio, GPT-4o can process text, images, and audio in a unified way. This unlocks new opportunities for building intelligent applications.
What Makes GPT-4o Special?
GPT-4o (the “o” stands for omni) is designed for seamless multi-modal interaction. Key capabilities include:
- Text: Natural language understanding and generation
- Image: Interpreting, analyzing, and describing visual input
- Audio: Listening, transcribing, and responding to speech
- Real-Time Interaction: Faster response times compared to GPT-4 Turbo
Getting Started with GPT-4o
To experiment with GPT-4o, you can use OpenAI’s API. Here’s how to set up a basic environment in Python:
pip install openai python-dotenvimport openai
import base64
# Example: Sending text and image together
with open("sample.png", "rb") as f:
image_bytes = f.read()
image_base64 = base64.b64encode(image_bytes).decode("utf-8")
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "What’s in this image?"},
{"type": "image_url", "image_url": f"data:image/png;base64,{image_base64}"}
]}
]
)
print(response.choices[0].message["content"])Building a Multi-Modal Chatbot
One practical application is a chatbot that can handle text, images, and audio seamlessly. For example:
- Users upload a photo, and the bot describes it.
- Users ask follow-up questions via text or voice.
- The bot replies in text or even generates audio responses.
Sample Workflow
# Pseudocode example
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "Describe this picture and summarize in one line."},
{"type": "image_url", "image_url": "https://example.com/car.jpg"}
]}
]
)
print(response.choices[0].message.content)Use Cases of GPT-4o
- Customer Support: Analyze screenshots or error photos directly in chat.
- Education: Explain diagrams and answer questions in real-time.
- Accessibility: Help visually impaired users by describing their surroundings.
- Creative Workflows: Combine text and visuals to co-create designs or content.
Best Practices
- Optimize prompts for multi-modal inputs by clearly structuring text + image/audio parts.
- Handle large images efficiently by resizing or compressing before sending.
- Use streaming responses for real-time applications like voice assistants.
- Monitor token and compute costs—multi-modal inputs are more expensive.
Conclusion
GPT-4o enables a new class of multi-modal applications that can understand and respond across text, images, and audio. For developers and data scientists, this means moving closer to natural human-computer interaction. Whether you’re building chatbots, educational tools, or accessibility solutions, GPT-4o is a powerful foundation.
"The future of AI lies in seamless multi-modal interaction, where machines understand us the way humans do." - Ashish Gore
If you’d like to collaborate or learn more about multi-modal AI applications, feel free to reach out through my contact information.