Financial fraud is a growing concern in our digital economy, with losses reaching billions of dollars annually. As a Lead Data Scientist at bluCognition, I've spent years developing and deploying machine learning solutions for fraud detection. In this comprehensive guide, I'll share the advanced techniques and strategies that have proven most effective in real-world FinTech applications.
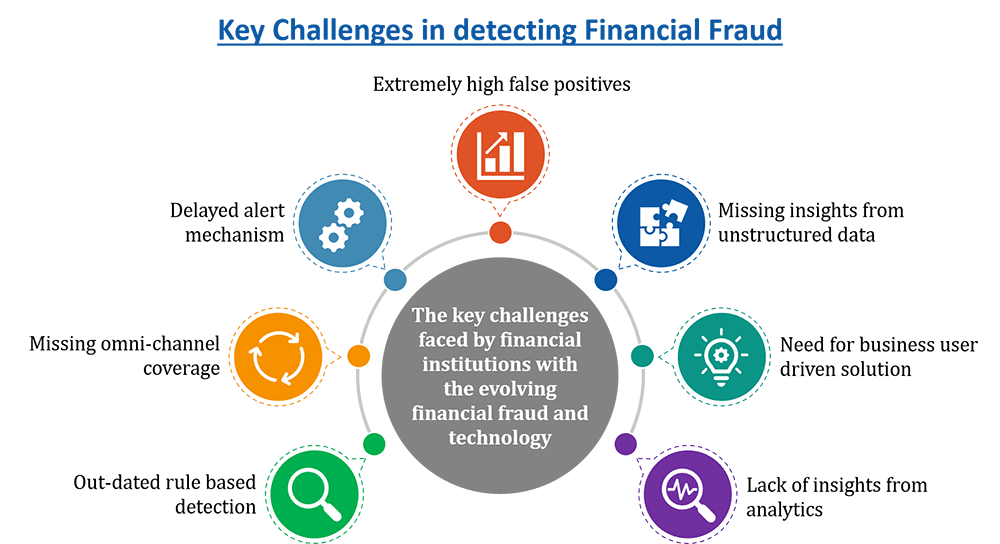
The Evolving Landscape of Financial Fraud
Financial fraud has become increasingly sophisticated, with fraudsters employing advanced techniques including:
- Document Manipulation: Forged bank statements, invoices, and identity documents
- Identity Theft: Synthetic identities and stolen personal information
- Transaction Fraud: Unauthorized payments and money laundering
- Account Takeover: Compromised user accounts and credentials
- Social Engineering: Manipulation of individuals and systems
Multi-Layered Fraud Detection Architecture
Effective fraud detection requires a comprehensive approach that combines multiple ML techniques and data sources:
1. Document Analysis and Verification
Document fraud is one of the most common types of financial fraud. Our approach combines multiple techniques:
Computer Vision for Document Authentication
import cv2
import numpy as np
from tensorflow.keras.models import load_model
from PIL import Image
import pytesseract
class DocumentAnalyzer:
def __init__(self):
self.template_model = load_model('document_template_classifier.h5')
self.forgery_detector = load_model('forgery_detector.h5')
def analyze_document(self, image_path):
# Load and preprocess image
image = cv2.imread(image_path)
processed_image = self.preprocess_image(image)
# Template matching
template_score = self.template_model.predict(processed_image)
# Forgery detection
forgery_score = self.forgery_detector.predict(processed_image)
# OCR extraction
text = pytesseract.image_to_string(image)
# Metadata analysis
metadata = self.extract_metadata(image)
return {
'template_confidence': template_score[0][0],
'forgery_probability': forgery_score[0][0],
'extracted_text': text,
'metadata': metadata,
'risk_score': self.calculate_risk_score(template_score, forgery_score, metadata)
}
def preprocess_image(self, image):
# Resize to standard size
image = cv2.resize(image, (224, 224))
# Normalize pixel values
image = image.astype(np.float32) / 255.0
# Apply data augmentation
image = self.apply_augmentation(image)
return np.expand_dims(image, axis=0)
def extract_metadata(self, image):
# Extract EXIF data
exif_data = self.get_exif_data(image)
# Analyze image properties
properties = {
'resolution': image.shape[:2],
'color_channels': image.shape[2] if len(image.shape) > 2 else 1,
'file_size': len(cv2.imencode('.jpg', image)[1]),
'creation_date': exif_data.get('DateTime', 'Unknown')
}
return propertiesText Analysis and Consistency Checking
import re
from datetime import datetime
import pandas as pd
class TextAnalyzer:
def __init__(self):
self.patterns = {
'account_number': r'\b\d{8,12}\b',
'routing_number': r'\b\d{9}\b',
'amount': r'\$?[\d,]+\.?\d{0,2}',
'date': r'\b\d{1,2}[/-]\d{1,2}[/-]\d{2,4}\b'
}
def analyze_bank_statement(self, text):
# Extract key information
account_info = self.extract_account_info(text)
# Validate consistency
consistency_score = self.check_consistency(account_info)
# Detect anomalies
anomalies = self.detect_anomalies(account_info)
return {
'account_info': account_info,
'consistency_score': consistency_score,
'anomalies': anomalies,
'risk_factors': self.identify_risk_factors(account_info, anomalies)
}
def extract_account_info(self, text):
info = {}
# Extract account number
account_match = re.search(self.patterns['account_number'], text)
if account_match:
info['account_number'] = account_match.group()
# Extract routing number
routing_match = re.search(self.patterns['routing_number'], text)
if routing_match:
info['routing_number'] = routing_match.group()
# Extract transactions
info['transactions'] = self.extract_transactions(text)
return info
def check_consistency(self, account_info):
score = 1.0
# Check date consistency
if 'transactions' in account_info:
dates = [tx['date'] for tx in account_info['transactions']]
if not self.are_dates_chronological(dates):
score -= 0.3
# Check amount formatting consistency
amounts = [tx['amount'] for tx in account_info.get('transactions', [])]
if not self.are_amounts_consistent(amounts):
score -= 0.2
return max(0, score)2. Transaction Monitoring and Anomaly Detection
Real-time transaction monitoring is crucial for detecting fraudulent activities as they happen:
Real-Time Anomaly Detection
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
import pandas as pd
class TransactionMonitor:
def __init__(self):
self.isolation_forest = IsolationForest(contamination=0.1, random_state=42)
self.scaler = StandardScaler()
self.is_trained = False
def train(self, historical_transactions):
# Feature engineering
features = self.extract_features(historical_transactions)
# Scale features
features_scaled = self.scaler.fit_transform(features)
# Train anomaly detector
self.isolation_forest.fit(features_scaled)
self.is_trained = True
def extract_features(self, transactions):
features = []
for tx in transactions:
feature_vector = [
tx['amount'],
tx['hour_of_day'],
tx['day_of_week'],
tx['merchant_category_code'],
tx['transaction_type'],
tx['is_weekend'],
tx['is_holiday'],
tx['distance_from_home'],
tx['time_since_last_transaction'],
tx['transaction_frequency_24h'],
tx['transaction_frequency_7d'],
tx['avg_transaction_amount_30d'],
tx['max_transaction_amount_30d']
]
features.append(feature_vector)
return np.array(features)
def predict_anomaly(self, transaction):
if not self.is_trained:
raise ValueError("Model must be trained before making predictions")
# Extract features for single transaction
features = self.extract_features([transaction])
features_scaled = self.scaler.transform(features)
# Predict anomaly
anomaly_score = self.isolation_forest.decision_function(features_scaled)[0]
is_anomaly = self.isolation_forest.predict(features_scaled)[0] == -1
return {
'is_anomaly': is_anomaly,
'anomaly_score': anomaly_score,
'risk_level': self.calculate_risk_level(anomaly_score)
}Behavioral Analysis
class BehavioralAnalyzer:
def __init__(self):
self.user_profiles = {}
self.behavioral_models = {}
def update_user_profile(self, user_id, transaction):
if user_id not in self.user_profiles:
self.user_profiles[user_id] = {
'transaction_history': [],
'spending_patterns': {},
'location_patterns': {},
'time_patterns': {}
}
profile = self.user_profiles[user_id]
profile['transaction_history'].append(transaction)
# Update spending patterns
self.update_spending_patterns(profile, transaction)
# Update location patterns
self.update_location_patterns(profile, transaction)
# Update time patterns
self.update_time_patterns(profile, transaction)
def analyze_behavioral_deviation(self, user_id, transaction):
if user_id not in self.user_profiles:
return {'deviation_score': 0, 'risk_factors': []}
profile = self.user_profiles[user_id]
deviation_score = 0
risk_factors = []
# Check spending deviation
spending_deviation = self.check_spending_deviation(profile, transaction)
deviation_score += spending_deviation['score']
risk_factors.extend(spending_deviation['factors'])
# Check location deviation
location_deviation = self.check_location_deviation(profile, transaction)
deviation_score += location_deviation['score']
risk_factors.extend(location_deviation['factors'])
# Check time deviation
time_deviation = self.check_time_deviation(profile, transaction)
deviation_score += time_deviation['score']
risk_factors.extend(time_deviation['factors'])
return {
'deviation_score': deviation_score,
'risk_factors': risk_factors,
'risk_level': self.calculate_risk_level(deviation_score)
}3. Network Analysis and Graph-Based Detection
Fraudsters often operate in networks. Graph-based analysis can reveal these connections:
import networkx as nx
import pandas as pd
from collections import defaultdict
class FraudNetworkAnalyzer:
def __init__(self):
self.graph = nx.Graph()
self.suspicious_patterns = []
def build_transaction_network(self, transactions):
# Create nodes for accounts, merchants, and devices
for tx in transactions:
# Add account nodes
self.graph.add_node(tx['account_id'], node_type='account')
# Add merchant nodes
self.graph.add_node(tx['merchant_id'], node_type='merchant')
# Add device nodes
if 'device_id' in tx:
self.graph.add_node(tx['device_id'], node_type='device')
# Add edges with transaction attributes
self.graph.add_edge(
tx['account_id'],
tx['merchant_id'],
amount=tx['amount'],
timestamp=tx['timestamp'],
transaction_id=tx['transaction_id']
)
def detect_suspicious_patterns(self):
patterns = []
# Detect circular transactions
circular_patterns = self.detect_circular_transactions()
patterns.extend(circular_patterns)
# Detect money laundering patterns
laundering_patterns = self.detect_money_laundering()
patterns.extend(laundering_patterns)
# Detect synthetic identity patterns
synthetic_patterns = self.detect_synthetic_identities()
patterns.extend(synthetic_patterns)
return patterns
def detect_circular_transactions(self):
circular_patterns = []
# Find cycles in the graph
cycles = list(nx.simple_cycles(self.graph.to_directed()))
for cycle in cycles:
if len(cycle) >= 3: # Minimum cycle length
total_amount = 0
for i in range(len(cycle)):
edge_data = self.graph.get_edge_data(cycle[i], cycle[(i+1) % len(cycle)])
if edge_data:
total_amount += edge_data.get('amount', 0)
if total_amount > 10000: # Threshold for suspicious amount
circular_patterns.append({
'pattern_type': 'circular_transaction',
'accounts_involved': cycle,
'total_amount': total_amount,
'risk_score': min(1.0, total_amount / 100000)
})
return circular_patterns
def detect_money_laundering(self):
laundering_patterns = []
# Find accounts with high transaction frequency
high_frequency_accounts = [
node for node in self.graph.nodes()
if self.graph.degree(node) > 100
]
for account in high_frequency_accounts:
# Analyze transaction patterns
neighbors = list(self.graph.neighbors(account))
transaction_amounts = [
self.graph.get_edge_data(account, neighbor).get('amount', 0)
for neighbor in neighbors
]
# Check for structuring (transactions just under reporting thresholds)
structuring_count = sum(1 for amount in transaction_amounts if 9000 <= amount < 10000)
if structuring_count > 5:
laundering_patterns.append({
'pattern_type': 'money_laundering',
'account': account,
'structuring_count': structuring_count,
'risk_score': min(1.0, structuring_count / 20)
})
return laundering_patternsAdvanced ML Techniques for Fraud Detection
Ensemble Methods
Combining multiple models often yields better results than any single model:
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
import xgboost as xgb
class FraudDetectionEnsemble:
def __init__(self):
self.models = {
'random_forest': RandomForestClassifier(n_estimators=100, random_state=42),
'logistic_regression': LogisticRegression(random_state=42),
'svm': SVC(probability=True, random_state=42),
'xgboost': xgb.XGBClassifier(random_state=42)
}
self.ensemble = VotingClassifier(
estimators=list(self.models.items()),
voting='soft'
)
def train(self, X_train, y_train):
# Train individual models
for name, model in self.models.items():
model.fit(X_train, y_train)
# Train ensemble
self.ensemble.fit(X_train, y_train)
def predict_proba(self, X):
return self.ensemble.predict_proba(X)
def predict(self, X):
return self.ensemble.predict(X)Deep Learning for Fraud Detection
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM, Embedding
from tensorflow.keras.optimizers import Adam
class DeepFraudDetector:
def __init__(self, input_dim, sequence_length=10):
self.input_dim = input_dim
self.sequence_length = sequence_length
self.model = self.build_model()
def build_model(self):
model = Sequential([
Dense(128, activation='relu', input_dim=self.input_dim),
Dropout(0.3),
Dense(64, activation='relu'),
Dropout(0.3),
Dense(32, activation='relu'),
Dropout(0.2),
Dense(1, activation='sigmoid')
])
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy', 'precision', 'recall']
)
return model
def train(self, X_train, y_train, X_val, y_val, epochs=100):
history = self.model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=epochs,
batch_size=32,
verbose=1
)
return history
def predict_proba(self, X):
return self.model.predict(X)Real-Time Fraud Detection Pipeline
Stream Processing Architecture
import kafka
from kafka import KafkaProducer, KafkaConsumer
import json
import threading
import time
class RealTimeFraudDetector:
def __init__(self, kafka_config):
self.kafka_config = kafka_config
self.producer = KafkaProducer(
bootstrap_servers=kafka_config['bootstrap_servers'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
self.consumer = KafkaConsumer(
kafka_config['input_topic'],
bootstrap_servers=kafka_config['bootstrap_servers'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.fraud_models = self.load_models()
self.running = False
def start_detection(self):
self.running = True
detection_thread = threading.Thread(target=self._detection_loop)
detection_thread.start()
def _detection_loop(self):
for message in self.consumer:
if not self.running:
break
transaction = message.value
# Perform fraud detection
fraud_result = self.detect_fraud(transaction)
# Send result to output topic
self.producer.send(
self.kafka_config['output_topic'],
{
'transaction_id': transaction['transaction_id'],
'fraud_probability': fraud_result['fraud_probability'],
'risk_score': fraud_result['risk_score'],
'risk_factors': fraud_result['risk_factors'],
'timestamp': time.time()
}
)
def detect_fraud(self, transaction):
# Extract features
features = self.extract_features(transaction)
# Get predictions from all models
predictions = {}
for model_name, model in self.fraud_models.items():
predictions[model_name] = model.predict_proba([features])[0][1]
# Ensemble prediction
fraud_probability = sum(predictions.values()) / len(predictions)
# Risk assessment
risk_factors = self.identify_risk_factors(transaction, features)
risk_score = self.calculate_risk_score(fraud_probability, risk_factors)
return {
'fraud_probability': fraud_probability,
'risk_score': risk_score,
'risk_factors': risk_factors,
'individual_predictions': predictions
}Model Performance and Monitoring
Key Metrics for Fraud Detection
- Precision: Percentage of flagged transactions that are actually fraudulent
- Recall: Percentage of actual fraud cases that are detected
- F1-Score: Harmonic mean of precision and recall
- False Positive Rate: Percentage of legitimate transactions flagged as fraud
- Cost of Fraud: Financial impact of undetected fraud
Continuous Learning and Model Updates
class ModelUpdater:
def __init__(self, model, retrain_threshold=0.05):
self.model = model
self.retrain_threshold = retrain_threshold
self.performance_history = []
def update_performance_metrics(self, precision, recall, f1_score):
self.performance_history.append({
'precision': precision,
'recall': recall,
'f1_score': f1_score,
'timestamp': time.time()
})
def should_retrain(self):
if len(self.performance_history) < 10:
return False
recent_performance = self.performance_history[-5:]
historical_performance = self.performance_history[-10:-5]
recent_f1 = sum(p['f1_score'] for p in recent_performance) / len(recent_performance)
historical_f1 = sum(p['f1_score'] for p in historical_performance) / len(historical_performance)
performance_degradation = historical_f1 - recent_f1
return performance_degradation > self.retrain_threshold
def retrain_model(self, new_data):
if self.should_retrain():
# Retrain model with new data
X_new, y_new = self.prepare_training_data(new_data)
self.model.fit(X_new, y_new)
# Reset performance history
self.performance_history = []
return True
return FalseBest Practices and Lessons Learned
1. Data Quality is Paramount
Ensure high-quality, clean data for training and inference. Implement robust data validation and cleaning pipelines.
2. Balance Precision and Recall
Adjust model thresholds based on business requirements. Higher precision reduces false positives but may miss some fraud cases.
3. Implement Human-in-the-Loop
Include human review for high-risk cases and use feedback to improve model performance.
4. Monitor Model Drift
Continuously monitor model performance and retrain when necessary to maintain effectiveness.
5. Privacy and Compliance
Ensure compliance with data protection regulations and implement privacy-preserving techniques when necessary.
Conclusion
Effective fraud detection in FinTech requires a multi-layered approach combining document analysis, transaction monitoring, behavioral analysis, and network analysis. By leveraging advanced ML techniques and maintaining continuous monitoring and improvement, organizations can significantly reduce fraud losses while minimizing false positives.
The key to success lies in understanding the specific fraud patterns in your domain, implementing robust data pipelines, and continuously adapting your models to evolving threats.
"Fraud detection is not just about building better models—it's about understanding the business context, maintaining data quality, and continuously adapting to new threats." - Ashish Gore
If you're interested in implementing advanced fraud detection systems for your organization or need guidance on specific techniques, feel free to reach out through my contact information.