From hyper-realistic portraits to fantastical landscapes, the world has been captivated by the explosion of AI-generated art. The technology powering many of the most popular tools like Stable Diffusion, Midjourney, and DALL-E is a class of generative models known as Diffusion Models. Their approach is both elegant and incredibly powerful, turning random noise into coherent, detailed images.
The Core Idea: From Image to Noise, and Back Again
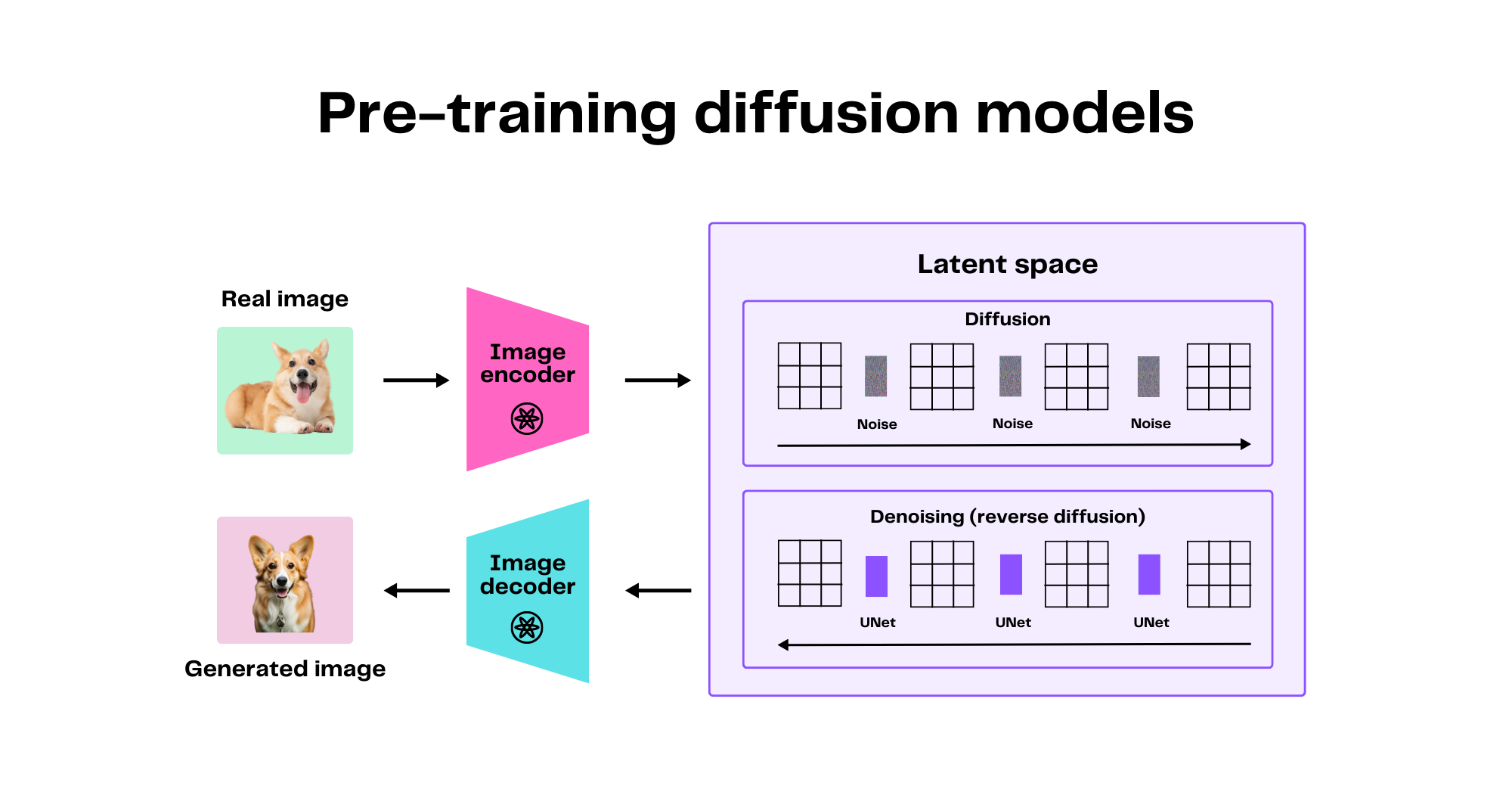
Diffusion models learn to generate images by mastering a two-step process:
- The Forward Process (Corruption): This is the training phase where the model learns how to destroy an image. It starts with a clean picture and, over hundreds of steps, incrementally adds a small amount of Gaussian noise until the original image is completely unrecognizable—just a field of static.
- The Reverse Process (Generation): This is where the magic happens. The model, now an expert "denoiser," starts with a new, completely random noise image. Step-by-step, it meticulously predicts and removes the noise, gradually revealing a clear, coherent image from the chaos.
Think of it like a sculptor who first learns how to turn a statue into a pile of dust, grain by grain, and in doing so, becomes an expert at reversing the process to form a statue from a cloud of dust.
Guiding the Chaos: The Role of the Text Prompt
But how does the model know to create a *specific* image, like "a cat riding a skateboard," instead of just a random one? This is achieved through guided diffusion. During the reverse (denoising) process, the model is given an extra piece of information: your text prompt.
The text prompt is converted into a numerical representation (embedding) by a text encoder. At each denoising step, this embedding is fed to the model, "steering" the process. The model isn't just removing noise; it's removing noise in a way that makes the emerging image progressively more consistent with the text description.
A Practical Example with Diffusers
The Hugging Face `diffusers` library has made it incredibly simple to run state-of-the-art diffusion models. The following code snippet shows a complete text-to-image pipeline that generates a picture from a simple prompt.
# A practical example of a text-to-image diffusion pipeline
from diffusers import AutoPipelineForText2Image
import torch
# 1. Load a pre-trained Stable Diffusion pipeline
# Using a float16 variant for faster inference on a GPU
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
variant="fp16"
).to("cuda")
# 2. Define the text prompt to guide image generation
prompt = "A photo of an astronaut riding a horse on mars."
# 3. Run the pipeline to generate the image from noise
image = pipeline(prompt).images[0]
# 4. Save the resulting image
image.save("astronaut_on_mars.png")
print("Image saved successfully!")
Why Diffusion Models are State-of-the-Art
While earlier models like GANs were groundbreaking, diffusion models have several key advantages that have led to their dominance in image generation:
- High-Quality Outputs: They are renowned for producing highly detailed, photorealistic, and diverse images.
- Stable Training: They are generally more stable and easier to train than GANs, which can be notoriously difficult to balance.
- Flexibility: The framework is easily extended to other tasks like inpainting, outpainting, and image-to-image translation.
The main trade-off has traditionally been slower inference speed due to the iterative denoising process, but recent advancements are rapidly closing this gap.
Conclusion
Diffusion models represent a paradigm shift in generative AI. By mastering the simple process of adding noise and then learning the complex art of reversing it under the guidance of human language, they have unlocked a new era of digital creativity. This elegant and powerful concept is the engine behind the current generative revolution, and its impact is only just beginning to be felt.
"The magic of diffusion isn't in creating something from nothing, but in sculpting a masterpiece from a canvas of pure chaos." - Ashish Gore
If you're interested in exploring how generative AI can be integrated into your applications, feel free to get in touch through my contact information.