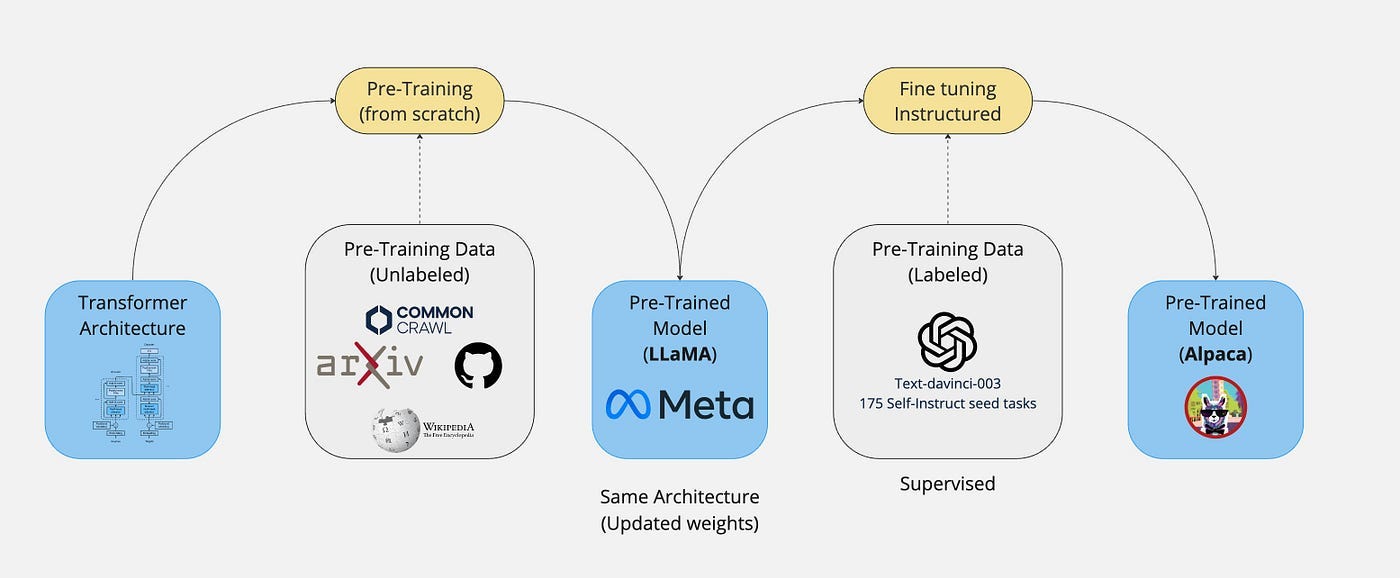
Fine-tuning large language models (LLMs) has become a key strategy for adapting them to specific domains. While LoRA and QLoRA are widely used due to their efficiency, the research landscape has evolved with new methods offering greater flexibility and performance.
Why Go Beyond LoRA?
LoRA works well for many tasks, but it has limitations in capturing complex domain-specific behaviors. Advanced techniques such as prompt tuning, adapters, and Mixture-of-Experts (MoE) can often provide better trade-offs between cost and performance.
Key Advanced Techniques
1. Prefix / Prompt Tuning
Prompt tuning involves training a small set of task-specific vectors (prompts) instead of updating the whole model. This is highly parameter-efficient and ideal when you need lightweight domain adaptation.
from peft import PromptTuningConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
peft_config = PromptTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = get_peft_model(model, peft_config)2. Adapter Modules
Adapters are small neural layers inserted between transformer blocks. They allow for efficient fine-tuning with minimal parameter updates.
from peft import LoraConfig, get_peft_model
adapter_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, adapter_config)3. Mixture-of-Experts (MoE)
MoE models, like Mistral’s Mixtral, route tokens through specialized expert networks. This reduces compute requirements while improving performance on diverse tasks.
# Pseudocode for MoE routing
if token.requires_math:
route_to_expert("math_expert")
elif token.requires_coding:
route_to_expert("code_expert")
else:
route_to_expert("general_expert")Choosing the Right Technique
- Prompt Tuning: Best for lightweight adaptation and low compute environments.
- Adapters: Suitable for medium-scale customization with moderate compute.
- MoE: Ideal for large-scale systems needing specialization and efficiency.
Practical Tips
- Start with parameter-efficient methods before full fine-tuning.
- Use
PEFTlibraries like Hugging Face’s implementation for quick experimentation. - Evaluate trade-offs: model size, training time, and inference cost.
- Benchmark performance on your domain-specific dataset before scaling.
Conclusion
Fine-tuning is evolving rapidly, and developers now have a toolbox of techniques beyond LoRA. Whether you need lightweight customization with prompt tuning or large-scale adaptability with MoE, choosing the right method can significantly improve your LLM applications.
"The future of LLM customization lies in parameter-efficient fine-tuning that balances cost, flexibility, and performance." - Ashish Gore
If you’d like to experiment with these fine-tuning methods for your projects, feel free to reach out through my contact information.